
2026 年 5 月 19 日の Google I/O で発表された Gemini Spark は、「端末を切っていてもクラウド側で動き続ける個人向け常駐エージェント」を打ち出した。土台は Gemini 3.5 と Google Antigravity だ。一方で 2026 年 5 月 1 日、米国防総省は AWS・Google・Microsoft・OpenAI・SpaceX・NVIDIA・Reflection AI・Oracle の 8 社と、IL6/IL7 (機密ネットワーク) 上での AI 配備契約を締結した。条件交渉で決裂した Anthropic は対象外となっている。業務系の常駐エージェント運用も、国家インフラ規模で動き出している。
OSS 側でも動きは早い。Nous Research が 2026 年 2 月にリリースした Hermes Agent は 3 ヶ月で GitHub スター 14 万超を獲得し、OpenRouter 上の利用数で 1 位に立った。永続メモリと自己改善 (実行ログから Markdown 形式のスキルファイルを自動生成して再利用) を備えたセルフホスト型エージェントで、商用クラウド側だけでなく自前運用の需要も一気に顕在化している。
つまり AI エージェントは「人が呼び出す」ものから「常駐して継続的にタスクを処理する」ものへと急速にシフトしている。
ただし、常駐型に切り替えた瞬間に運用面の難しさが一気に増す。社内導入や PoC を経て本番運用に進めようとしたチームが最初にぶつかる落とし穴は決まって 3 つだ。権限、監査、そしてコストである。
この記事ではそれぞれの落とし穴を具体的に整理し、さくらのクラウドを前提にした国産環境での実装指針まで踏み込んで書く。
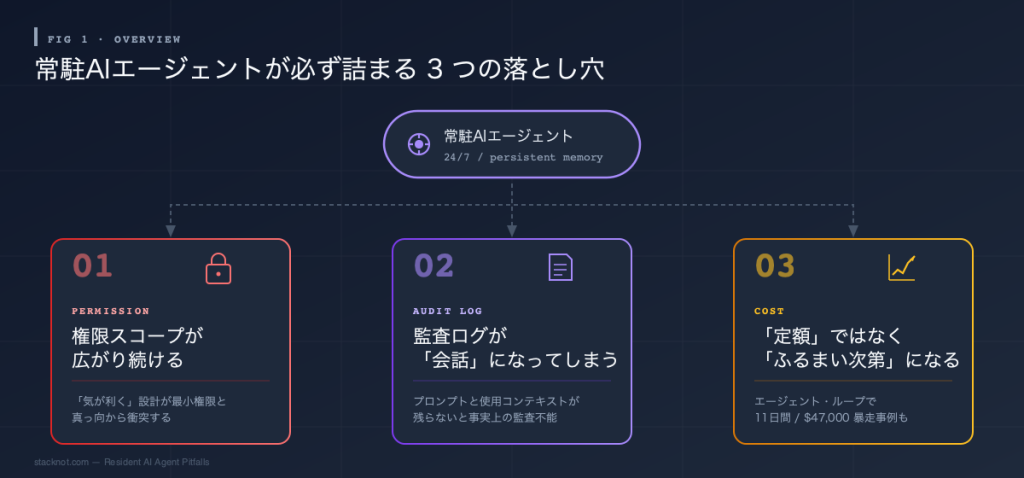
落とし穴 1: 権限スコープが広がり続ける
常駐エージェントは「気が利く」ほど価値が出る。社内 Wiki も読める、Slack も投稿できる、CRM のレコードも更新できる、本番 DB のクエリも投げられる ── そう設計したくなる。
ところがこのアプローチは最小権限の原則と真っ向から衝突する。エージェントが暴走したときの被害範囲が、付与した権限すべてに広がるからだ。加えて、プロンプトインジェクションや内部関係者による誘導で意図しない操作が走るリスクは、エージェントの能力と比例して大きくなる。2026 年 4 月には Pillar Security が Google Antigravity のサンドボックス脱出脆弱性を公開し、5 月には Microsoft Semantic Kernel 経由でプロンプトから RCE に繋がる経路が報告された。抽象的なリスクではなくなっている。
そのため、実装側でやるべきことは大きく 2 つある。
ひとつはツール権限を役割ベースで束ねること。「営業ドメイン用エージェント」「経理ドメイン用エージェント」のように責務を切って、横断的な強権限を持つ単一エージェントを作らない設計が安全だ。
もうひとつは操作の可逆性で権限を分けること。読み取り系は広めに開放してもよいが、書き込み・削除・送信といった不可逆操作には人間の承認ステップを挟む。Anthropic の Claude Agent SDK や OpenAI の Responses API も、この「Human-in-the-loop」前提の設計を強く推している。
なお、さくらのクラウド上で動かす場合は 2026 年 2 月提供開始のIDポリシー機能が使える。エージェント用サービスプリンシパルに対して「実行可能な操作」と「操作対象リソース」を明示的に絞り込める仕組みだ。コントロールプレーン側で先に縛っておくのが、被害範囲を最小化するいちばん地味で効く一手になる。
落とし穴 2: 監査ログが「会話」になってしまう

では、監査ログはどう設計すべきか。従来の監査ログは「誰が・いつ・何のリソースに・どんな API を投げたか」を時系列で残せばよかった。AI エージェントを介すと、この構造が一気に崩れる。
エージェントの動作を後から追うには、最低でも以下をそろえて残す必要がある。
- ユーザーの指示プロンプト (原文)
- システムプロンプトと利用したコンテキスト (RAG で参照した文書 ID 含む)
- モデルが選んだツール呼び出しと引数
- ツールの実行結果
- 最終的にユーザーに返した応答
ここを残さないと、「なぜそのエージェントが本番 DB に DELETE を投げたのか」をインシデント後に追跡できない。つまり、プロンプトを残していないログは AI エージェントにおいては事実上の監査不能に近い。
実装面では、エージェントの実行フレームワーク (LangGraph、Mastra、Pydantic AI など) が出すトレースを構造化ログとして抜き出す。そのうえで、長期保管できるオブジェクトストレージに必ず流す設計が要る。コンプライアンス要件が厳しい組織であれば、改ざん検知付きストレージや WORM 設定も視野に入る。なお、さくらのクラウドは 2026 年に SOC2 Type1 を取得しており、監査証跡を国産環境に閉じたまま残せるという観点でも選択肢に入りやすくなった。
落とし穴 3: コストが「定額」ではなく「ふるまい次第」になる
さらに厄介なのがコストだ。常駐エージェントのコスト構造は、従来のサーバー型ワークロードとは性質が違う。CPU やメモリではなく入出力トークン量と推論回数で青天井に膨らむからだ。
特に怖いのは、エージェントが自分自身でツールを呼び続けてしまう「エージェント・ループ」だ。判断を誤ったエージェントが同じツール呼び出しを再帰的に繰り返し、半日でひと月分の API 予算を溶かすケースは実際に起きている。海外では再帰ループに入ったエージェントが 11 日間動き続け、$47,000 の API 課金を発生させた事例も報告されている。
ここで対策の柱は 3 つある。
- 1 タスクあたりの最大ステップ数を必ず設定する。LangGraph では
recursion_limit(デフォルトは 25) を環境に合わせて調整するか、自前ループにmax_iterationsを必ず持たせる。 - モデルを段階分けする。判断は Haiku、複雑タスクのみ Sonnet/Opus、のようにルーターを噛ませることでコストは数倍単位で動く。
- チーム別の予算アラートを出す。Anthropic Console の Workspaces 機能では、ワークスペース単位で月次の spend limit と通知メールを設定できる。閾値を超えたら自動停止できる仕組みを自前のダッシュボードと組み合わせて用意したい。
さくらのクラウドでの実装指針
ここからは国産環境、特にさくらのクラウドを前提にした具体的な構成パターンを書く。
2026 年 3 月 27 日、デジタル庁はさくらのクラウドをガバメントクラウドとして正式認定した。305 項目の技術要件をすべて満たした国産唯一のサービスで、AWS・Google Cloud・Azure・OCI と並ぶ 5 番目の選択肢になった。これは行政系・準公共系のワークロードを国産環境で動かす選択肢が一段現実的になったことを意味する。AI エージェントの導入においても、特にデータを国外に出したくない案件ではさくらのクラウドが第一候補に上がるケースが増えてきた。
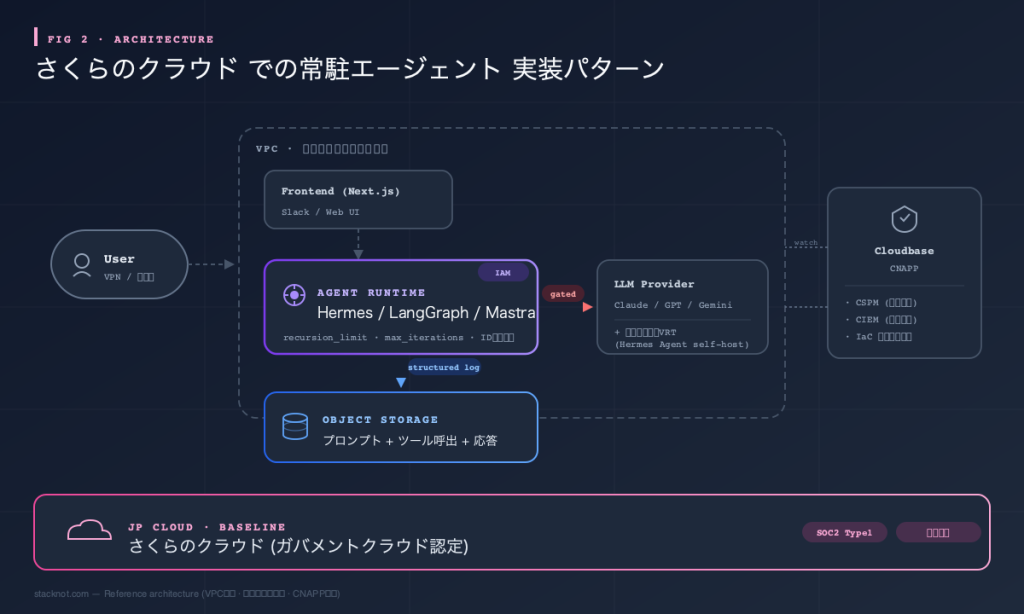
ネットワーク設計: VPC とパケットフィルタで実行環境を隔離する
エージェントの実行ノードは、業務システムと同居させないのが鉄則だ。さくらのクラウドではスイッチ+ルーターで VPC 相当の独立セグメントを切り、外向き通信はパケットフィルタで LLM プロバイダーの IP レンジに絞り込む。社内システムへのアクセスは、VPN/専用線経由のホワイトリスト方式にする。マルチクラウド構成を取るなら、2026 年 4 月に GA となった AWS Interconnect (multicloud) のような専用接続サービスを使う選択肢もある。インターネット経由のトークン送信を避けられるからだ。
監査ログ: オブジェクトストレージへの長期保管
エージェントの構造化ログはオブジェクトストレージ (さくらのクラウド オブジェクトストレージ、もしくは S3 互換ストレージ) に流す。ログのキー設計を yyyy/mm/dd/agent_id/trace_id.json のような階層にしておくと、後からの監査検索が現実的なコストで回せる。
セキュリティ運用: CNAPP との連携
2026 年 4 月 27 日、さくらインターネットは国産クラウドセキュリティ「Cloudbase」と業務提携の基本合意書を締結した。常駐エージェントを動かすクラウド構成の設定ドリフトや、過剰な IAM 権限の検知は、CNAPP 系製品に任せると運用負荷が大きく下がる。Cloudbase は CSPM (設定ミス検知)・CIEM (過剰 IAM 権限検知)・IaC ドリフト検知をマルチクラウド統合で提供しており、エージェント用サービスプリンシパルが知らぬ間に権限を増やされる経路の継続監視に直接効く。国産クラウド × 国産 CNAPP の組み合わせは、データ主権を重視する案件で今後の標準解になりそうだ。
コスト管理: GPU ノードと従量課金の落とし穴
自前ホストの推論エンジンを使う場合、さくらの高火力シリーズを使うシーンが増える。ベアメタルの「高火力 PHY」、コンテナ実行の「高火力 DOK」、時間貸し VM の「高火力 VRT」と用途別に選べる構成だ。ただし、ここでも常時稼働ではなくスケジュール起動とアイドル停止を前提に組まないと、夜間や週末のコストがそのまま無駄になる。Slack 通知付きの予算アラートを最初から組み込んでおきたい。
セルフホスト型エージェントの選択肢: Hermes Agent
商用 API ではなく自前で常駐エージェントを立てるなら、Nous Research の Hermes Agent (MIT License) を高火力 VRT に載せる構成が現実的な選択肢に入る。バックエンド LLM は OpenRouter 経由で差し替えでき、データは自社環境に閉じる。Telegram・Slack・WhatsApp など複数のフロントを 1 プロセスで束ねられる点も常駐運用と相性がよい。
ただし、Hermes Agent の魅力でもある自動スキル生成には注意が要る。エージェントが実行ログから新しいスキルを Markdown として作って永続化していくため、生成スキルそのものが新しい権限経路になりうる。落とし穴 1 で触れた最小権限の原則を Hermes Agent でも貫くなら、生成スキルファイルのレビュー・承認フローを必ず挟む運用に倒すべきだ。
実装チェックリスト
導入前に最低限確認したい項目を 10 個に絞ると、こうなる。
- エージェントの役割は責務単位で分割されているか
- 不可逆操作には承認フローが入っているか
- ツール権限は最小権限になっているか
- プロンプト・ツール呼び出し・応答が構造化ログとして残っているか
- ログは長期保管され、改ざん検知が必要か検討済みか
- 最大ステップ数・最大トークン数のガードレールがあるか
- モデル段階分けでコスト最適化されているか
- チーム別予算アラートが設定されているか
- 実行環境がネットワーク的に業務システムから隔離されているか
- 設定ドリフトと過剰権限の自動検知が回っているか
よくある質問
Q. 常駐 AI エージェントを国産クラウドで動かすメリットは何ですか?
A. データを国外に出さずに済む点と、行政・準公共系で必須となるガバメントクラウド適合性が確保できる点です。さくらのクラウドは 2026 年 3 月に国産唯一でガバクラ認定を受けており、データ主権要件のある案件で第一候補になります。
Q. LangGraph の recursion_limit はどこまで下げるべきですか?
A. デフォルトは 25 です。タスクが平均 10 ステップ程度で完結する設計なら 30〜50 で十分。100 超を設定するなら、コスト上限と組み合わせて二重のガードレールを敷くべきです。
Q. Anthropic Workspaces の spend limit だけでコスト暴走は止められますか?
A. 月次の上限を超えると API アクセスが止まる仕組みですが、検知から停止までにラグがあります。アプリ側で max_iterations、トークン上限、Slack 通知を多層で組み合わせるべきです。
まとめ
常駐 AI エージェントは確実に来る潮流だが、運用設計を後回しにすると本番投入後に必ず痛い目を見る。権限・監査・コストの 3 軸で先に設計を固めることが第一歩だ。そのうえで、国産クラウド (特にさくらのクラウド) を選ぶ場合は VPC・オブジェクトストレージ・CNAPP・GPU 従量管理を組み合わせれば、実用的な常駐エージェント基盤は十分に組める。
PoC のあいだは「気が利く一体型エージェント」が魅力的に見えるが、本番では役割分割と監査の徹底こそが運用の差になる。


